论文概述
本文发表在AAAI 2017上,作者是Ramesh Nallapati, Feifei Zhai和Bowen Zhou,论文链接:https://arxiv.org/abs/1611.04230 。
这篇文章提出了一个基于RNN的模型,来完成抽取式自动文本摘要任务。模型公式具有可解释性,并且可以利用已有的abstractive summary数据训练我们的extractive model。
SummaRuNNer模型
作者把抽取式摘要(extractive summarization)问题转化为一个序列分类(sequence classification)问题:对文章的每句话都做一个二分类,被选中为摘要的一部分就标注为1,未被选中就标注为0。当然了,因为使用了RNN,每次做分类的时候,都会考虑之前句子的分类情况。
GRU
本模型使用的是RNN的变体——GRU。$u$被称作update gate,$r$被称作reset gate,$W$和$b$是模型需要训练的参数,$h$是真实值隐状态( real-valued hidden-state)。GRU的计算公式如下:
\begin{aligned} \mathbf { u } _ { j } & = \sigma \left( \mathbf { W } _ { u x } \mathbf { x } _ { j } + \mathbf { W } _ { u h } \mathbf { h } _ { j - 1 } + \mathbf { b } _ { u } \right) \\\\ \mathbf { r } _ { j } & = \sigma \left( \mathbf { W } _ { r x } \mathbf { x } _ { j } + \mathbf { W } _ { r h } \mathbf { h } _ { j - 1 } + \mathbf { b } _ { r } \right) \\\\ \mathbf { h } _ { j } ^ { \prime } & = \tanh \left( \mathbf { W } _ { h x } \mathbf { x } _ { j } + \mathbf { W } _ { h h } \left( \mathbf { r } _ { j } \odot \mathbf { h } _ { j - 1 } \right) + \mathbf { b } _ { h } \right) \\\\ \mathbf { h } _ { j } & = \left( 1 - \mathbf { u } _ { j } \right) \odot \mathbf { h } _ { j } ^ { \prime } + \mathbf { u } _ { j } \odot \mathbf { h } _ { j - 1 } \end{aligned}
文本表示
处理NLP问题,首先需要做的就是文本表示。研究目的是抽取一篇文章的摘要,而一篇文章是由若干句子构成,一句话又包含了若干单词。所以本文先后在单词级别和句子级别建模最后得到文本表示,细节如下:
- 首先对单词向量化(Word Embedding)。本文使用Google的Word2Vec工具训练得到词向量(100维)。
- 使用双向的RNN(也就是Bi-GRU)计算每个位置的隐状态表示(hidden state representations),输入是第一步得到的词向量。
- 使用另外一个双向RNN(同样是Bi-GRU),输入是上一步的隐状态表示做average pooling。
- 最后通过一个非线性转换得到整个文本的表示。$d$是文本表示,$W_d$是参数,$N_d$代表隐状态数量,$\left[ \mathbf { h } _ { j } ^ { f } , \mathbf { h } _ { j } ^ { b } \right]$是上一步双向RNN的隐状态输出。计算文本表示的公式如下:
通过以上几个步骤我们得到了文本表示。
分类层
然后,我们就可以预测每个句子是否被选中作为摘要的一部分。这其实是一个分类问题。我们遍历每个句子,使用二分类的方法判断这个句子需不需要加入摘要里面去,对应于一个logistic layer。计算公式如下: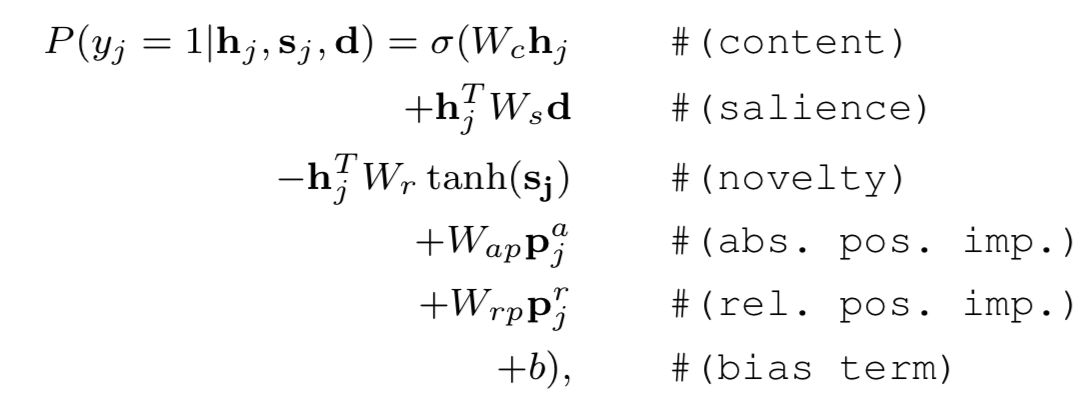
解读一下公式中的字母:
- $W_c,W_s,W_r,W_{ap},W_{rp},b$ 均为模型可训练参数;
- $y_i$代表这句话是否被摘要选中(选中就是1);
- $h_j$是句子级RNN输出的隐状态;
- $d$是经过非线性转换的文本表示;
- $s_j$是第$j$个位置的动态摘要表示,这里提出如下公式计算动态摘要表示:
- ${ p } _ { j } ^ { a }$是绝对位置向量(absolute positional embeddings),${ p } _ { j } ^ { r }$是相对位置向量(relative positional embeddings)
通过分类层的公式计算,我们可以预测每句话被选中到摘要的概率。
到此为止,整个模型的架构已经全部搭建完成,如下图,就是SummaRuNNer的模型结构: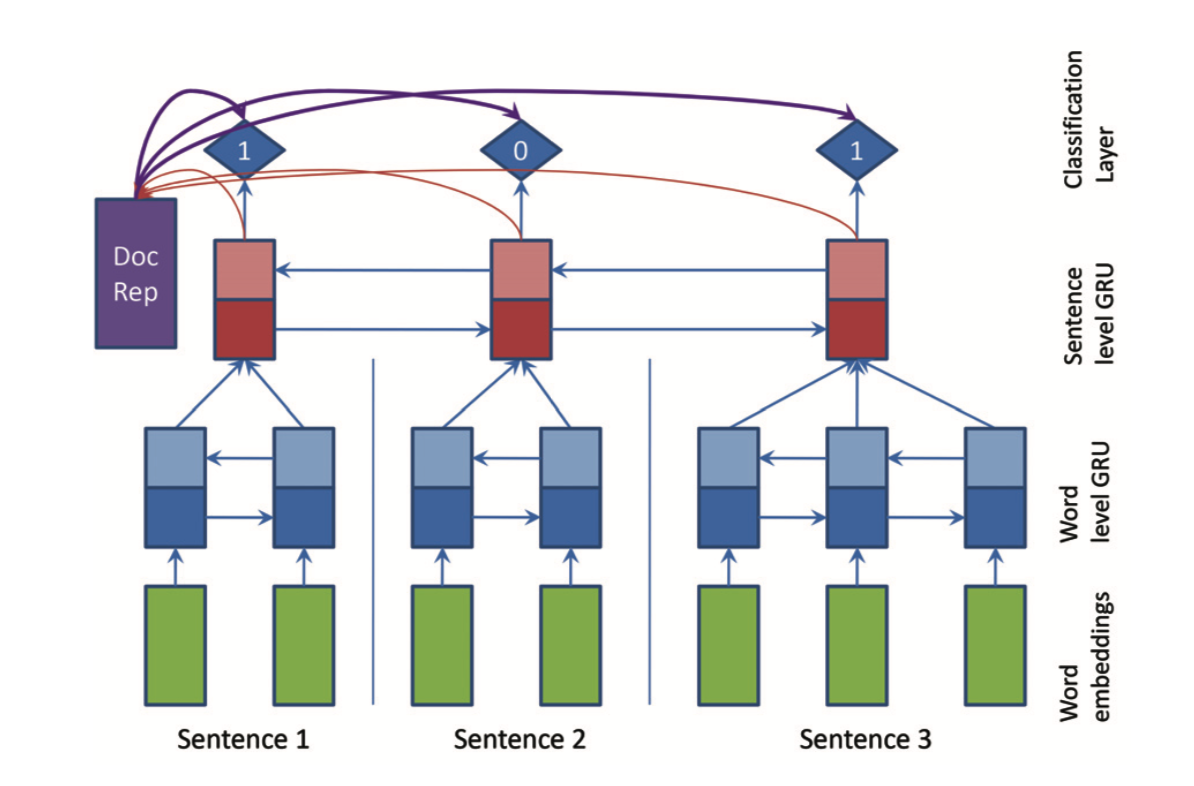
损失函数
损失函数(loss function)如下:
$l ( \mathbf { W } , \mathbf { b } ) = - \sum _ { d = 1 } ^ { N }\sum _ { j = 1 } ^ { N_d } ( y _ { j } ^ { d } \log P \left( y _ { j } ^ { d } = 1 | \mathbf { h } _ { j } ^ { d } , \mathbf { s } _ { j } ^ { d } , \mathbf { d } _ { d } \right) \\\\ +\left( 1 - y _ { j } ^ { d } \right) \log \left( 1 - P \left( y _ { j } ^ { d } = 1 | \mathbf { h } _ { j } ^ { d } , \mathbf { s } _ { j } ^ { d } , \mathbf { d } _ { d } \right) \right)$
其实就是一个负对数似然(negative log-likelihood),我们的目标就是优化损失函数,使其最小。
Extractive Training
但是目前很多文本摘要数据集的摘要部分都是人为概括出来的,所以不能直接用于SummaRuNNer这个模型的抽取式训练。论文中使用贪心算法来抽取文章的句子添加到训练时使用的参考文摘里。
Abstrctive Training
在SummaRuNNer这个模型的基础上,作者在后面增加一个RNN Decoder,使得模型也可以被摘要是地训练。
以上两种训练方法讲解的比较少,想要深入了解可以参考论文原文。
之所以对两种训练方法讲解的较少,是因为本人发现github中关于本论文的代码实现使用的数据集在训练集验证集测试集中,已经直接标注了哪句话被摘要选中,所以我们在实际训练的时候可以当做一个单纯的分类问题来考虑。
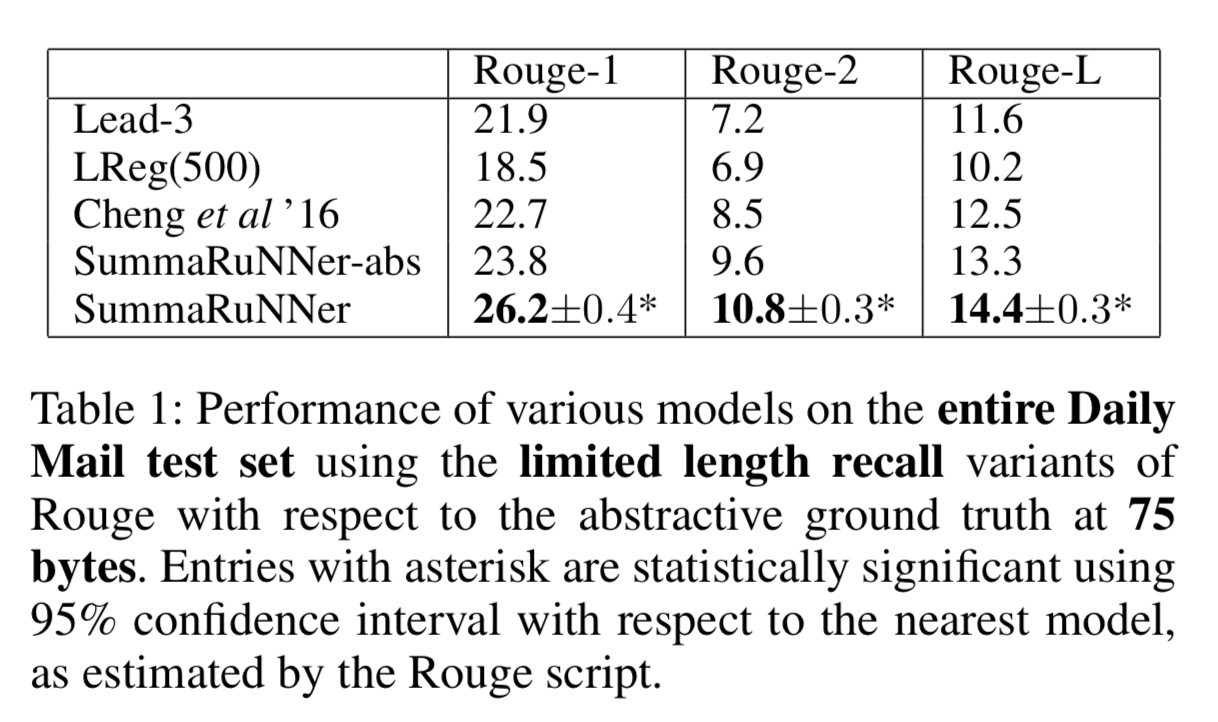
实验与结果
数据集
- CNN/DailyMail语料: 196557 training documents, 12147 validation documents and 10396 test documents,平均而言,每个document有28个句子,每个summary中有3-4个句子;
- DUC2002语料:567个document;
模型设置
- word embedding:使用Google的Word2Vec训练得到,100维
- vocabulary size:150k
- 每篇文章的最大句子数:100
- 每句话的最多单词数:50
- hidden state size:200
- batch size:64
- optimizer:adadelta
- 使用了gradient clipping
- 基于验证集损失的early stopping
实验结果